Zero Shot Voice Conditioning for Denoising Diffusion TTS Models
This post presents "Zero Shot Voice Conditioning for Denoising Diffusion TTS Models", a method for speech synthesis from unseen speakers using only a single reference with no training.
Abstract:
We present a novel way of conditioning a pretrained denoising diffusion speech model to produce speech in the voice of a novel person unseen during training. The method requires a short (~3 seconds) sample from the target person, and generation is steered at inference time, without any training steps. At the heart of the method lies a sampling process that combines the estimation of the denoising model with a low-pass version of the new speaker’s sample. The objective and subjective evaluations show that our sampling method can generate a voice similar to that of the target speaker in terms of frequency, with an accuracy comparable to state-of-the-art methods, and without training.
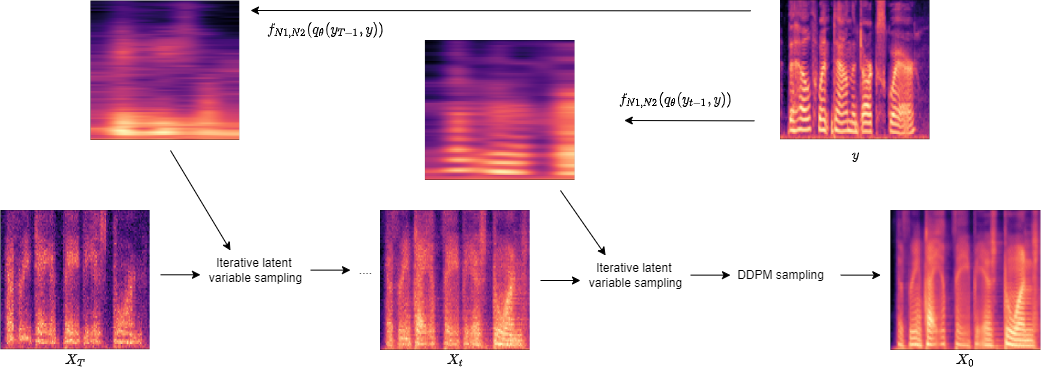
Samples generated from our mathod using the Grad-TTS Diffusion Denoising probabalistic model with Iterative latent variable sampling.
- Grad-TTS - Sample generated from the baseline Grad-TTS model without our sampling method.
- Reference - Speech of a reference speaker.
- Our - sample from the Grad-TTS model using our sampling method. Conditioned on the reference.
Voice Conversion Examples
| Grad-TTS | Reference | Our |
|---|---|---|
Non Speech References Examples
| Grad-TTS | Reference | Our |
|---|---|---|
N2 Values Scale
ILVR stopping step constant at 6
| Grad-TTS | Reference | Our, N2 = 2 | Our, N2 = 8 | Our, N2 = 18 | Our, N2 = 24 | Our, N2 = 32 |
|---|---|---|---|---|---|---|
ILVR Stopping Step Values Scale
N1 constant at 1, N2 constant at 18
| Grad-TTS | Reference | Our, step = 2 | Our, step = 4 | Our, step = 6 | Our, step = 8 | Our, step = 10 |
|---|---|---|---|---|---|---|
References
[1]. Popov V, Vovk I, Gogoryan V, Sadekova T, Kudinov M. Grad-tts: A diffusion probabilistic model for text-to-speech. InInternational Conference on Machine Learning 2021 Jul 1 (pp. 8599-8608). PMLR.
[2]. Choi J, Kim S, Jeong Y, Gwon Y, Yoon S. Ilvr: Conditioning method for denoising diffusion probabilistic models. arXiv preprint arXiv:2108.02938. 2021 Aug 6.